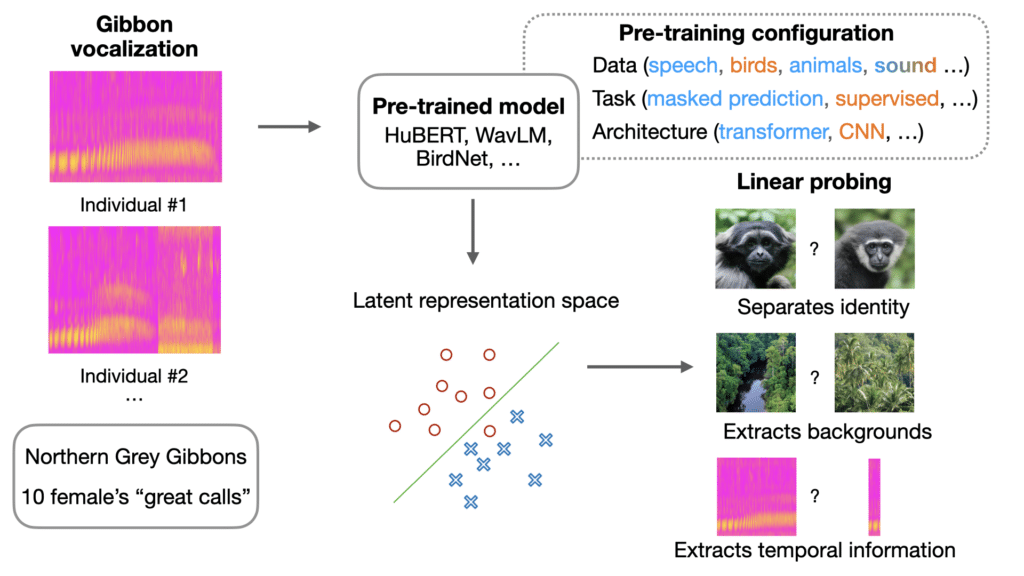
 We explored knowledge transfer capabilities of pre-trained speech models with vocalizations from the closest living relatives of humans: non-human primates. We assessed model performance in identifying individual gibbons based on their songs using linear probing. When compared to models pre-trained on bird songs or general audio, speech-based models appear to produce rich bioacoustic representations, encoding vocal content information over background noise and effectively capturing the temporal dynamics of gibbon songs.
We explored knowledge transfer capabilities of pre-trained speech models with vocalizations from the closest living relatives of humans: non-human primates. We assessed model performance in identifying individual gibbons based on their songs using linear probing. When compared to models pre-trained on bird songs or general audio, speech-based models appear to produce rich bioacoustic representations, encoding vocal content information over background noise and effectively capturing the temporal dynamics of gibbon songs.
Jules Cauzinille, Benoît Favre, Ricard Marxer, Dena Clink, Abdul Hamid Ahmad, and Arnaud Rey.
Investigating Self-Supervised Speech Models’ Ability to Classify Animal Vocalizations: The Case of Gibbon’s Vocal Signatures
In Interspeech 2024, 132–36. ISCA. — @HAL