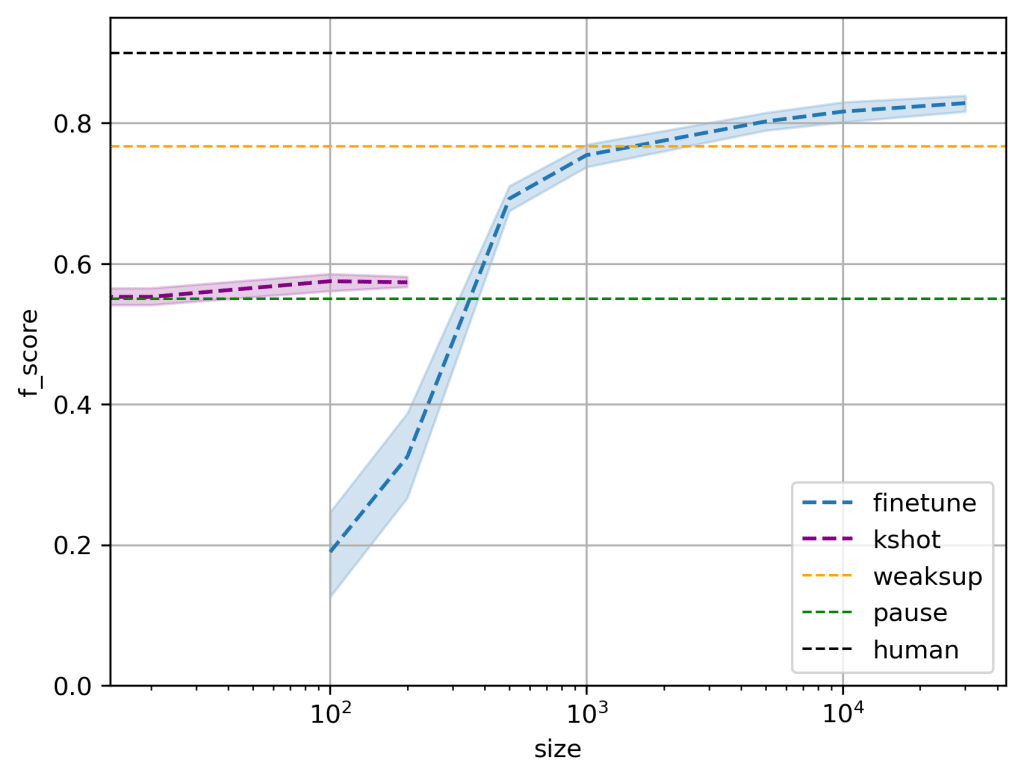
We compared three machine-learning approaches for segmenting discourse units. The performance of each method (“f_score”) is plotted against the number of training tokens (“size”, in log-scale). “weaksup” means data-programming weak supervision, in which the training set is annotated by an automatic noisy labeller based on a manually written set of labeling rules; “finetune” means fine-tuning an LLM (RoBERTa) with varying amounts of hand-labelled data; “kshot” means prompting GPT-2 with different numbers of examples. Standard fine-tuning of an LLM emerges as the most effective method. It reaches the same performance as the “weaksup” approach while relying on a more straightforward training procedure. The prompting “kshot” approach was lagging behind. Although the models used with the prompting approach are improving rapidly, their intrinsic opacity makes systematic error analysis almost impossible.
Laurent Prévot and Philippe Muller. 2025.
Dialogue & Discourse 16 (2): 35–73. — @HAL