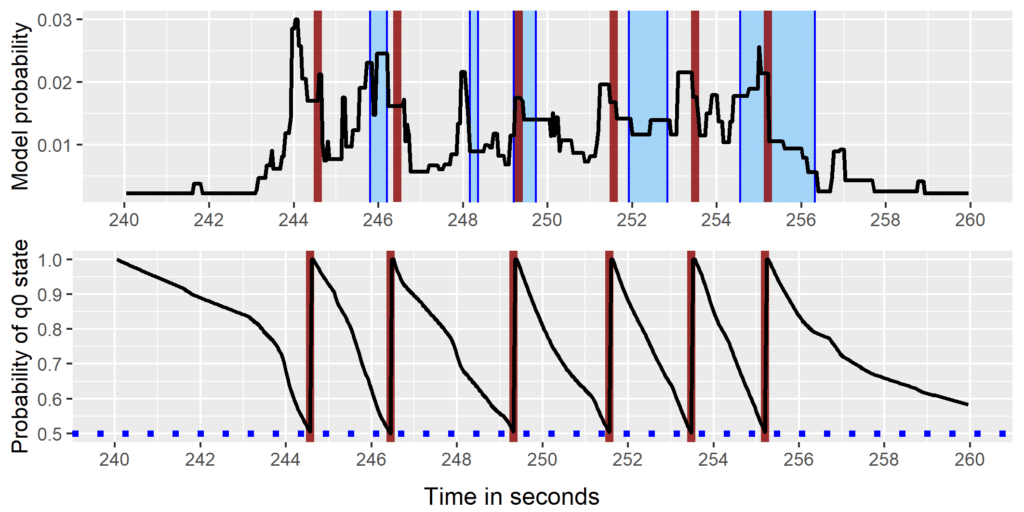
During natural interactions, listeners produce reactions in response to speakers, a phenomenon known as conversational feedback. Feedback depends on the main speaker’s production. Our model uses multimodal features to predict when and what type of feedback will occur during conversations. Throughout the conversations, the model computes the feedback probability (the black curve on the top panel) and predicts feedback when this probability exceeds a given threshold (vertical red lines). Predicted feedback and observed feedback (blue areas) are then compared to assess model performance. By leveraging features like morpho-syntax, prosody, and gestures in the speaker’s production, it identifies key moments that trigger listener responses. This computational model provides precise descriptionf of the context in which feedback occurs.
Auriane Boudin, Roxane Bertrand, Stéphane Rauzy, Magalie Ochs, and Philippe Blache
A Multimodal Model for Predicting Feedback Position and Type During Conversation
Speech Communication 159 (April 2024):103066 — @HAL