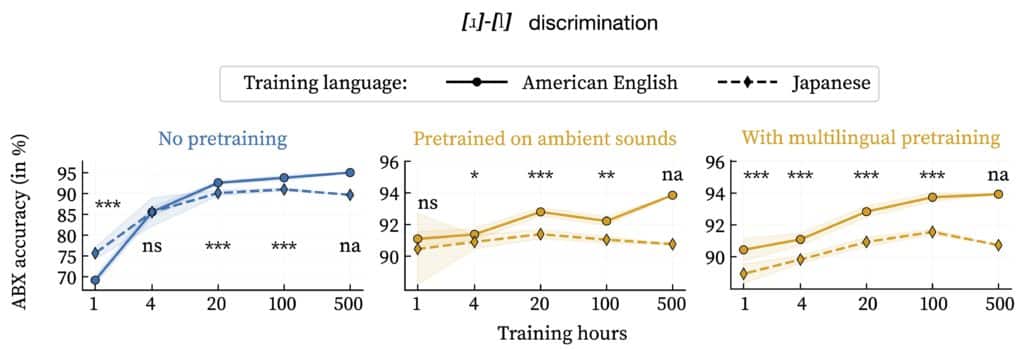
The discrimination between [ɹ] and [l] sounds –as in the English minimal pair “rip” and “lip”– can be learned by an unsupervised model such as the self-supervised contrastive predictive coding model (Oord et al. 2018). Performance –ranging from 50% at chance to 100% for perfect discrimination– depends on a number of factors, including: the hours of training data; the contrastive value of the phonemes in the training language (e.g., American English vs. Japanese); and, most relevant here, on how model parameters are initialised before training.
The figure contrasts the outcomes for random initialisation, pre-training on ambient sounds (animal vocalisation and other environmental sounds, excluding human speech and music) and pre-training on multilingual speech (18 European languages, excluding Germanic languages). Pre-training strategies have a strong impact on the shape of the developmental trajectories predicted by the model. This effect may be interpreted in terms of evolutionary influences affecting internal developmental processes.
Figure adapted from
Maxime Poli, Thomas Schatz, Emmanuel Dupoux, et Marvin Lavechin
Modeling the Initial State of Early Phonetic Learning in Infants
2025. Language Development Research 5 (1). – @HAL